Een zoekmachine bouwen #2 - De eerste problemen
11 januari 2018In deze serie blogs waarin ik een zoekmachine aan het ontwikkelen ben, wil ik niet alleen laten weten wat er goed gaat, maar ook wat er misgaat. Dat is tenslotte veel leuker.
Allereerst, voor het inladen van pagina's gebruik ik de CURL lib. Deze methode zag er als volgt uit:
public function download($url)
{
$ch = curl_init();
$timeout = 5;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$data = curl_exec($ch);
curl_close($ch);
return $data;
}
Hierbij is een aantal kleine problemen ontstaan. Omdat er natuurlijk meerdere crawlers tegelijk lopen om niet te hoeven wachten op iedere afzonderlijke download, kan het binnenhalen van de pagina langer duren dan normaal gesproken het geval zou zijn.
Daarnaast worden op deze manier eventuele redirects niet gevolgd en geldt de timeout niet voor de volledige duur maar alleen voor het maken van de connectie.
Tevens kan het niet ondersteunen van een certificaat voor problemen zorgen in het geval dat SSL geforceerd wordt, dus kies ik er nu voor om het certificaat niet te controleren. Om te compenseren voor de relatief hoge CPU load heb ik de timeout naar 10 gezet.
public function download($url)
{
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_TIMEOUT, $timeout);
$data = curl_exec($ch);
curl_close($ch);
return $data;
}
Met de bovenstaande aanpassingen heb ik dit deel van de code aanzienlijk verbeterd en de crawler iets flexibeler gemaakt. Toch bleven er pagina's "hangen" in de crawler, ongeacht mijn CURL settings. Omdat de crawlers via PHP CLI worden gedraaid, is er vanuit de parser geen max execution time, dus heb ik deze zelf aan moeten geven door middel van set_time_limit(15). De praktijk is echter anders en het script wordt niet per definitie afgekapt. Tijd voor wat rigoreuzere oplossingen dus.
De crawlers worden per iteratie opnieuw ingeladen, zodat ik tijdens het crawlen kan ontwikkelen en ze niet handmatig op hoef te starten na iedere update. Omdat de crawlers in een infinite loop zitten, worden ze continu opnieuw aangeroepen:
#!/bin/bash while true do php crawler.php done
Met dit bash script blijft het probleem met de max execution time nog gewoon bestaan. Nu ondersteunt GNU in de terminal ook de functie timeout, wat mijn probleem oplost:
#!/bin/bash
while true
do
timeout 60 php crawler.php
done
Op deze manier kan ik ervoor zorgen dat scripts nooit langer dan 60 seconden draaien. Een handige toevoeging.
Daarnaast heb ik om snel de crawlers te kunnen starten en stoppen een settings tabel gemaakt in de database, waar ik simpelweg pause op true of false kan zetten. :-)
En dan het grootste probleem met dit soort applicaties, waarin de hoeveelheid data snel oploopt: performance. Omdat ik niet exact bij houd wanneer pagina's geindexeerd worden, gebruik ik de bandbreedte als peiler. En die ziet er als volgt uit:
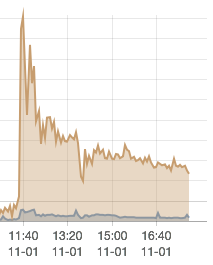
Met een snelheid die zo snel daalt, gaan we natuurlijk geen fatsoenlijke zoekmachine krijgen. Bij het vorige project heb ik zelf een database engine in C geschreven die exact deed wat ik nodig had, maar de broncode hiervan ben ik allang weer kwijt en ik heb weinig zin om het opnieuw te doen.
Een andere optie die ik gebruikt heb is Berkeley DB. Deze database is gebaseerd op het key-value principe. Je kunt het je voorstellen als een tabel met slechts twee kolommen: een key en een value. Doordat dit zeer efficiënt is, is een dergelijke database dus ook gigantisch snel. Het nadeel is daarentegen: met key-value pairs kun je relatief weinig data in één keer opslaan.
Op dit moment gaat mijn voorkeur uit naar een hybridevariant van MySQL en Berkeley DB. Met name bij het maken van het algoritme waarmee de websites daadwerkelijk geïndexeerd worden, is een snelle database een absolute must. Zowel voor het wegschrijven als voor het uitlezen.
Al het ontwikkelwerk wordt uitgevoerd op een VPS van een tientje per maand en een single CPU met 1GB RAM. Het streven is om op deze VPS een relatief goed werkende zoekmachine te hebben en daarna pas op te schalen naar meer rekenkracht en geheugen. Waarom? Omdat meer rekenkracht tegen iets aangooien omdat het niet snel genoeg is, vaak een verkeerde oplossing is. Pas als ik tevreden ben met de resultaten op deze VPS, ga ik nadenken over bijvoorbeeld een quad core met wat meer geheugen. :-)
(FYI: load average: 4.86, 4.72, 4.75, dus hij heeft het druk met z'n ene CPU'tje!)
Al met al... nog niet eens een werkend geheel en de eerste problemen steken de kop op!
Internet Marketing
Een zoekmachine bouwen #8 - PageRank, Zoeken, etc.Geplaatst op 5 december 2019
Een zoekmachine bouwen #7 - Backlinks & Tabellen
Geplaatst op 22 juli 2018
Een zoekmachine bouwen #6 - Full page cache
Geplaatst op 13 juli 2018
Een zoekmachine bouwen #5 - Een stap verder
Geplaatst op 11 juli 2018
Auteur: Edwin Dijk
TimeTick producten
Urenregistratie software
Gratis urenregistratie software